6.4 pivoting to longer format
Aktuell befindet sich jede Variable in einer Spalte und jede Messung entspricht einer Zeile. Was müssen wir also tun, wenn wir die Bodentemperatur aus allen Tiefen in einer Abbildung darstellen wollen und nicht in mehreren?!
💡 R basiert auf einer long-format Datendarstellung (auch gestapelt genannt), wohingegen Excel auf einem wide-format basiert. Das Transformieren zu einem long-format ist eine der häufigsten Datentransformationen um den Datensatz tidy zu bekommen.
Wir brauchen einen langen Vektor aller Bodentemperaturen, um diesen darzustellen und erreichen es mit der Funktion pivot_longer() aus dem tidyr:: package.
# Erstelle einen langen Vektor der Bodentemperatur
koog_day %>%
pivot_longer(cols = starts_with("st")) %>% # Durch helper functions können wir alle Spalten auswählen, die mit "st" beginnen
ggplot(aes(daily, value, color = name)) +
geom_line()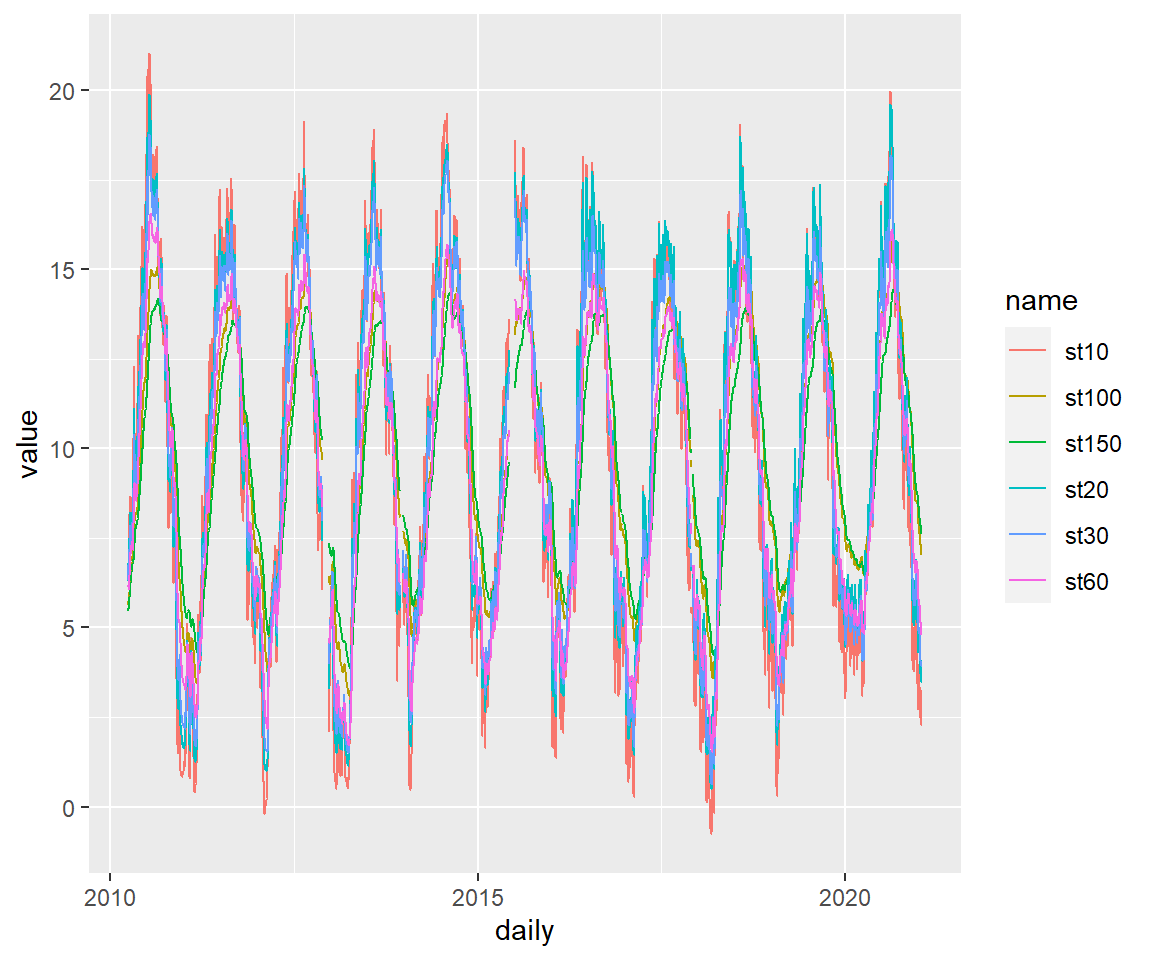
# Wähle nur die 10 und die 150 cm Tiefe aus durch Angabe der Spaltennamen
koog_day %>%
pivot_longer(cols = c("st10", "st150")) %>% # Durch helper functions können wir alle Spalten auswählen, die mit "st" beginnen
ggplot(aes(daily, value, color = name)) +
geom_line()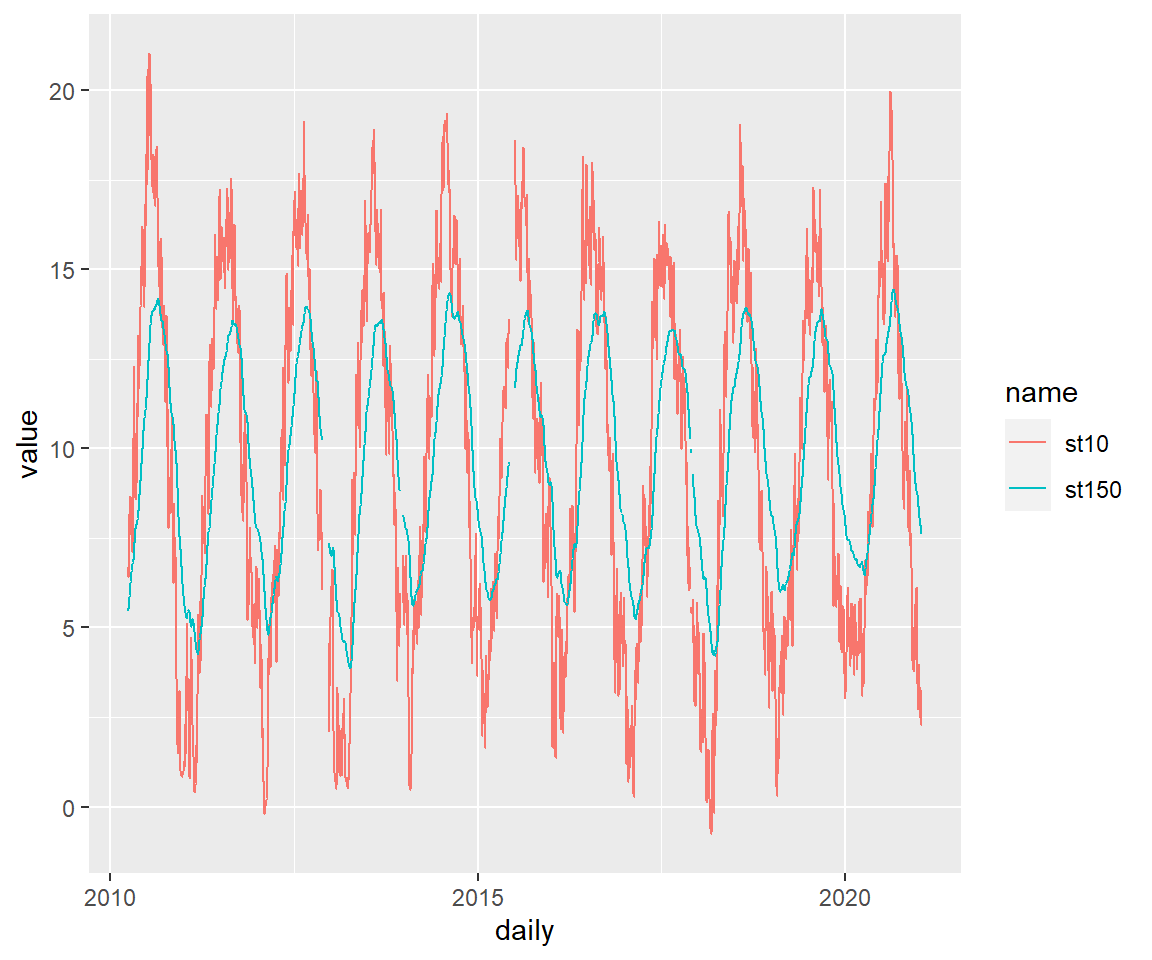
Beim pivoting können wir uns Informationen in den Zeilennamen auch zunutze machen, um diese in den Neuen Variablenbezeichnungen zu integrieren. Dabei empfiehlt sich eine Spaltenbeschriftung zu wählen, die auf dieses Schema leicht übernommen werden kann. Eine Möglichkeit die Bodentemperatur in 10 cm Tiefe zu codieren wäre st_10.
# Erstelle ein tibble im wide format
test <- tibble(
st_10 = rnorm(n = 10, mean = 10, sd = 1),
st_20 = rnorm(n = 10, mean = 9, sd = 1),
st_30 = rnorm(n = 10, mean = 8, sd = 1)
)
test
## # A tibble: 10 x 3
## st_10 st_20 st_30
## <dbl> <dbl> <dbl>
## 1 10.9 10.9 7.03
## 2 11.2 9.25 8.11
## 3 10.3 10.4 9.52
## 4 10.4 8.14 8.78
## 5 9.49 8.28 7.89
## 6 11.1 9.22 7.47
## 7 9.26 8.99 7.89
## 8 11.4 9.80 8.39
## 9 10.9 7.91 9.04
## 10 11.0 8.65 8.28
# Erstelle tibble test_long im long format
test_long <- test %>%
pivot_longer(cols = contains("st"), names_to = c("Parameter", "Depth"), values_to = "Wert", names_sep = "_") # Gebe an wie die Informationen im Spaltenname getrennt sind
test_long
## # A tibble: 30 x 3
## Parameter Depth Wert
## <chr> <chr> <dbl>
## 1 st 10 10.9
## 2 st 20 10.9
## 3 st 30 7.03
## 4 st 10 11.2
## 5 st 20 9.25
## 6 st 30 8.11
## 7 st 10 10.3
## 8 st 20 10.4
## 9 st 30 9.52
## 10 st 10 10.4
## # ... with 20 more rows